Entropy and Afrobeats
Background
i’ve been curious about how much entropy is generally contained in Afrobeats lyrics.
entropy measures how much variance is contained within a given corpus of data — it’s a measure of disorder or randomness in a system.
i find this particularly interesting because we can use entropy to measure the level of surprise contained within song lyrics.
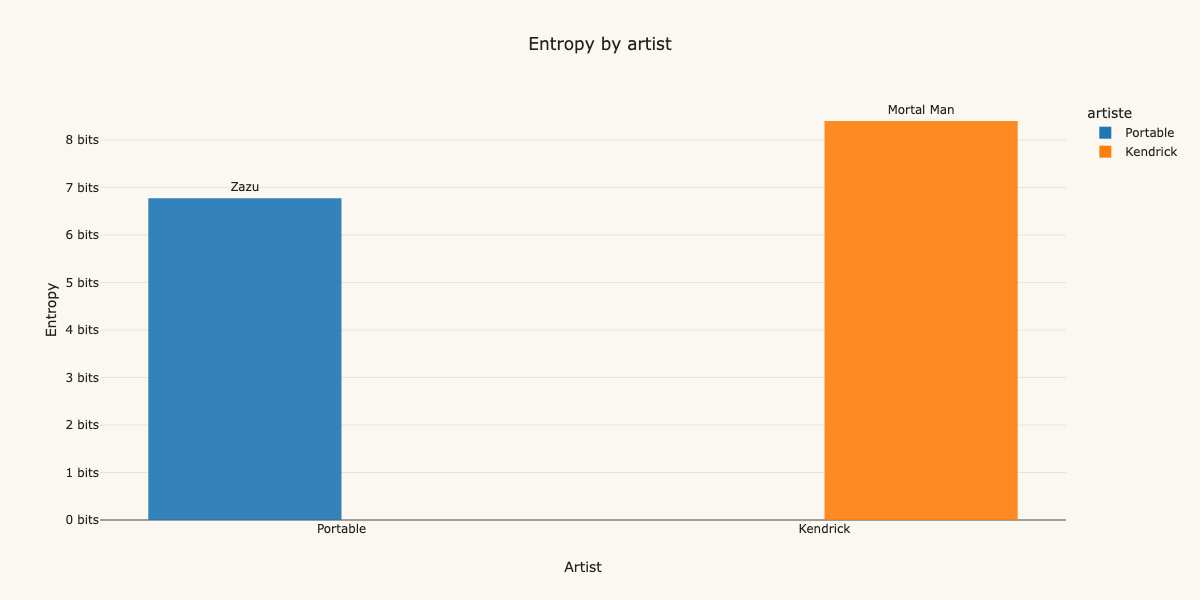
“Zazu” by Portable can be efficiently encoded in 6.8 bits per word, which is interesting when you consider that Kendrick Lamar’s Mortal Man can be encoded in 8.4 bits per word.

i appreciate that these are both two wildly different songs/genres! 😅
in this article i explore how entropy has varied across different music genres over time.
Technical details
props to Claude Shannon for laying the foundation of information theory and defining tractable mathematical tools for efficiently encoding messages over inherently noisy communication channels.
we live in a world riddled with uncertainty, so it’s only natural that transmitting a message from a to b risks losing context from its original source. this potential loss of context is called noise and Shannon formulated ways to measure this loss.
Shannon also proposed a means to measure the optimal way to encode these messages through a given message channel, based on the distribution of probabilities across all potential message states. the measure of this is called entropy.
in other words, given the likelihood of potential states in a probabilistic system, we can calculate how many bits will be required to optimally encode an average message drawn from this system.
entropy indicates how much surprise exists within the samples in a given sample space. for song lyrics, we could use entropy to measure how likely it is for the same words to occur in a given song.
songs with repetitive lyrics will have low entropy and songs with varied lyrics will have high entropy.
we can view this lack of variance as a bias towards a known more probable state
Shannon defined entropy as:
$$ \text{Entropy} = -\sum_{x \in X}p(x) \log p(x) $$
Where,
$$ p(x) \text{ is the probability of an event } x \text{ occuring} $$
$$ -logp(x) \text{ is the information content of x in the event that it occurs, given the probability } p(x) $$
$$ \sum_{x \in X} \text{represents the sum over all probable information content in states x} $$
for this project, i’ve calculated the entropy for some of the most prevalent songs across afrobeats, pop, and hip-hop since 2020, and i found the results to be quite interesting!
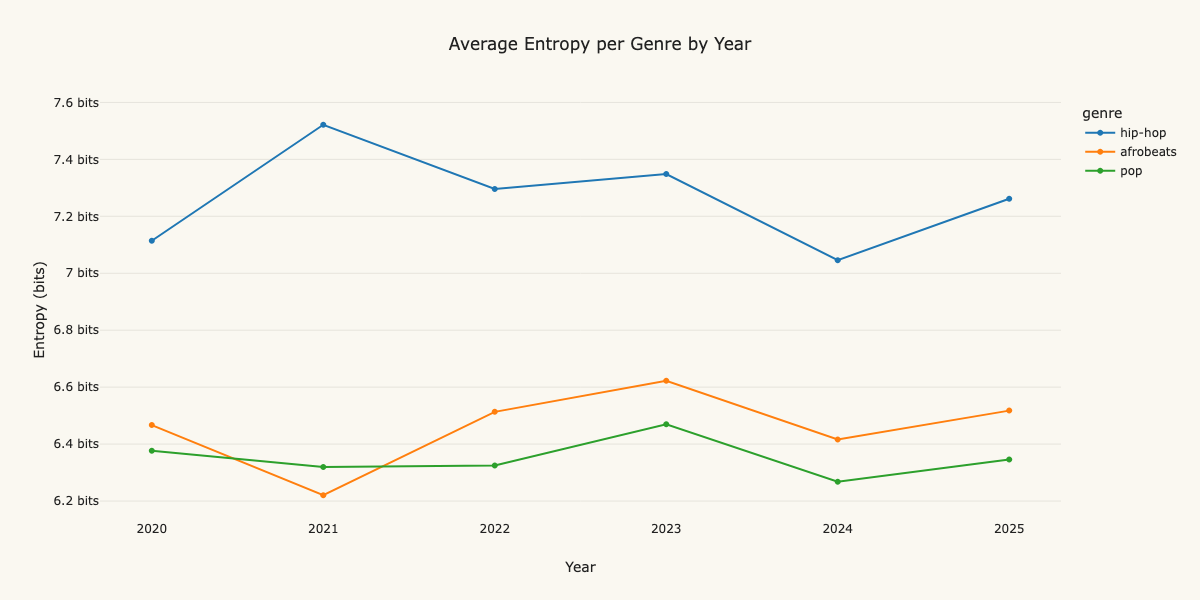
we can see that hip-hop has the largest entropy across all genres ~7.3 bits, which makes intuitive sense considering the variance of hip-hop lyrics in contrast to other genres.
we can also see that since 2021 the average entropy in Afrobeats lyrics has sharply increased from ~6.2 bits to ~6.6 bits.
in the same period, global pop music (excluding afrobeats 😉) has increased from 6.3 bits to 6.4 bits.
this plausibly indicates that over time Afrobeats lyrics are getting more diverse and varied based on the distribution of words used within each song.
i also found it interesting to visualise how the entropy for specific artists has changed over time by song.
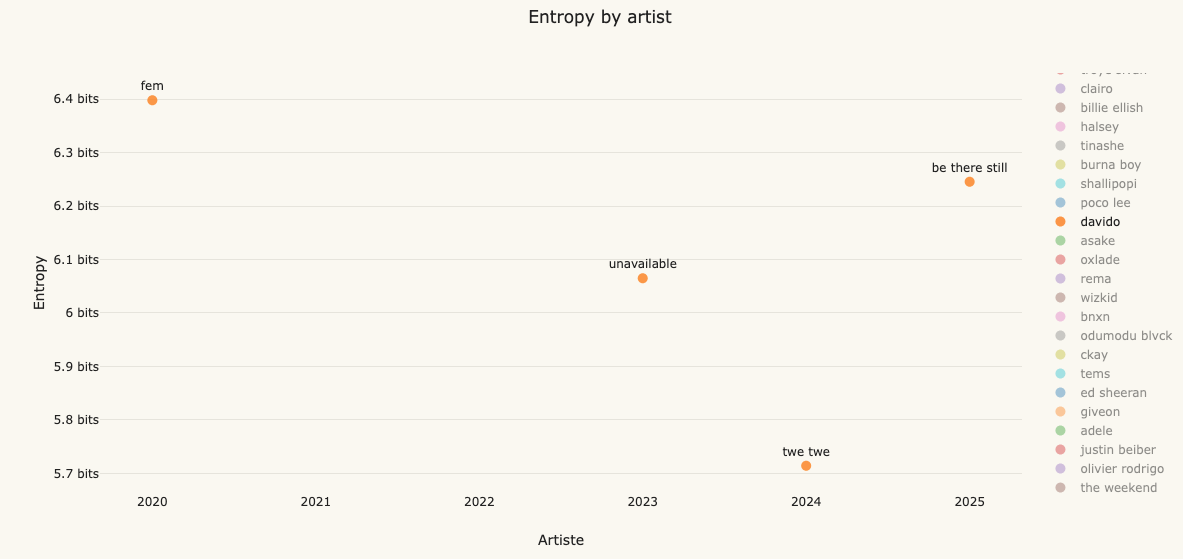
for example, in the graph above we can see that Davido’s 2020 hit “FEM” has an entropy of 6.3bits, however his catchy 2024 song “Twe Twe” has an entropy of 5.71 bits which is significantly less. this makes intuitive sense because the words “Twe twe” occur repeatedly in the song, hence less entropy is observed.
Methodology
i’ve measured the entropy within a given song’s lyrics by tokenizing the words based on a whitespace and new line tokenizer.
afterwards, i calculated the frequency of each tokenised word within the song (i.e how many times the word occurred), and then computed the likelihood, p(x) of that word occurring as:
$$ p(x) = \frac{frequency(x)}{\text{total word count}} $$
Dataset
for each genre, i’ve considered lyrics from ~5 charting songs per genre per year (since 2020).
in total the dataset includes 89 songs. lyrics sourced from google search !
Considerations
the current dataset of 5 songs per genre per year is quite limited and i’d be excited to see more work done in this area/revisit this project with a much larger dataset.
our current tokeniser simply uses whitespaces and new lines but this could also be improved to use a subword tokeniser to detect repeated subwords within the lyrics.
entropy only provides a measure of repeated words in song lyrics, rather than a measure of lyrical depth.
Conclusion
as time progresses and culture cross pollinates across borders (both physical and social), i’d be interested in seeing how the entropy within and across these genres changes.
given the increasing levels of globalisation, one could argue that a potential trajectory of global culture is the gradual convergence towards a shared system of self-expression.
this would ultimately lead to less overall entropy in the arts (and culture!), while leading to a more unified (and conformist?) cultural landscape.
another trajectory is further variance and divergence across cultures, rather than the aforementioned convergence.
this trajectory would lead to increased overall entropy in the arts, where we would see wildly varied forms of art and expression. very few patterns point to this trajectory (so far) given the societal and economical (read capitalistic) pressures that actively push against individuality and free thought.
it’s left as an exercise for the reader to determine which of either trajectories is most likely and ideal :p